前回の補足。以下はテストデータのグラフである。

次は主成分分析、ヒストグラムベース異常検知、k-近傍法の図である。


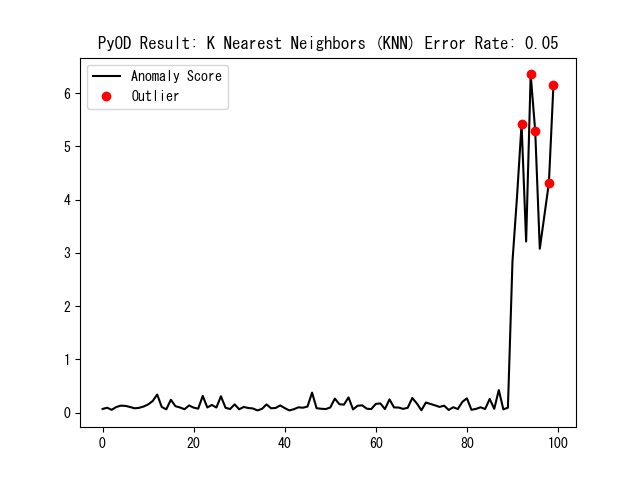
以下、各手法について簡単に解説する。
主成分分析:変数間の連関性をもとに多変数を少数の主成分に縮約する。
k-近傍法:任意のデータ点について、そのk番目に近い近傍との距離を異常度として用いる。
Isolation Forest: この手法では、木の集合を用いてデータの区分けが行われる。Isolation Forestは、その点が構造の中でいかに孤立しているかを示す異常度スコアを与える。それゆえ異常度スコアは正常なデータ点から外れた点を識別するために用いられる。Isolation Forestは多次元データで高い性能を発揮する。
ヒストグラムに基づく異常検知法:効率的な教師なし学習手法である。特徴間の独立を仮定し、ヒストグラムを構築することにより異常スコアを計算する。多変量アプローチよりも高速であるが、精度は落ちる。
クラスタリングに基づく局所外れ値因子法:データを大きなクラスターと小さなクラスターに分類する。異常度スコアはその点が属するクラスターのサイズと、最も近い大型クラスターとの距離で計算される。