ブログ終了のお知らせ
これまで長年にわたりまして統計・データサイエンスの技術面に特化したブログを執筆してまいりましたが、
健康上の理由により終了することといたしました。
長年のご愛読誠にありがとうございました。
ブログ主:nicjps230
ガウス混合モデルによる市場レジームの判定
株価の動きをそのボラティリティなどに基づいて分類し、現在どの状態にあるかの手掛かりにする、という分析は、本ブログの本年6月の投稿記事でもとりあげました。今回紹介するのは、別の手法によるアプローチで、"ガウス混合モデル"による多次元データのケースの分類を用いています。
ガウス混合モデル(Gaussian Mixture Model、GMM)とは、複数のガウス分布(正規分布)を組み合わせた確率モデルです。データが複数のガウス分布から生成されていると仮定し、それらの分布を混合することで、複雑なデータ分布を表現します。これはk-meansクラスタリングのように、多次元データに基づくケースの分類に主として適用されます。今回も、Medium英文記事をベースとしています。この記事におけるガウス混合モデル適用のポイントは、(1)分類に用いる変数として"終値の変化(リターン)"と"出来高の変化"を取り上げている、(2)ガウス混合モデルの計算にsklearnライブラリのGaussianMixtureを用いている、ことです。原記事には分類結果の散布図のみ示されていますが、ここではその分類ごとに色分けした終値の折れ線グラフを追加しました。
まず、ライブラリのインポートと共通の設定です。
# ライブラリのインポート import pandas as pd import numpy as np from datetime import date, datetime, timedelta import matplotlib.pyplot as plt import yfinance as yf from sklearn.mixture import GaussianMixture import matplotlib.cm as cm import warnings warnings.simplefilter(action="ignore", category=FutureWarning) import os os.environ["OMP_NUM_THREADS"] = "2" # 共通設定 ticker = "^N225" # str_prodはデータを取得する期間(例: 1d、5d、1mo、3mo、1y、2y、5y、10y、ytd、max) str_prod = "18mo" # str_itvlはデータの間隔(例: 1m、2m、5m、15m、30m、60m、90m、1h、1d、5d、1wk、1mo、3mo) str_itvl = "1d" # matplotlibのカラーマップ str_colormap = 'viridis'
次に、区間で色分けする折れ線グラフの描画関数です。
# 区間色分け折れ線グラフの描画関数 def colored_plot(x, y, labels, ticker): unique_labels = np.unique(labels) colors = cm.get_cmap(str_colormap, len(unique_labels)) color_map = {label: colors(i) for i, label in enumerate(unique_labels)} # プロット開始 plt.figure(figsize=(10, 5)) # ラベルの変化点で分割して線を描く start = 0 for i in range(1, len(labels)): if labels[i] != labels[i-1]: plt.plot(x[start:i+1], y[start:i+1], color=color_map[labels[i-1]], label=f'label {labels[i-1]}') start = i # 最後の区間 plt.plot(x[start:], y[start:], color=color_map[labels[-1]], label=f'label {labels[-1]}') plt.xlabel("Date") plt.ylabel("Price") plt.title(ticker+" Close Price by Regime") plt.grid(True) plt.show()
次に、株価データをダウンロードし、分類に用いるデータを正規化して、LGMMモデルをあてはめます。
# 株価データの獲得 df = yf.download(ticker, period=str_prod, interval=str_itvl, multi_level_index=False).reset_index() data = np.column_stack((df['Close'].pct_change().dropna(), df['Volume'].pct_change().dropna())) # データの正規化 mean = np.mean(data, axis=0) std = np.std(data, axis=0) data_normalized = (data - mean) / std # LGMMモデルのあてはめ lgmm = GaussianMixture(n_components=3, random_state=42) lgmm.fit(data_normalized) labels = lgmm.predict(data_normalized)
最後に、図を表示します。
# 散布図の表示 plt.scatter(data_normalized[:, 0], data_normalized[:, 1], c=labels, cmap=str_colormap) plt.title('LGMM Clustering of '+ticker+' Data') plt.xlabel('Normalized Return') plt.ylabel('Normalized Volume Change') plt.savefig('spy_lgmm_plot.png') plt.show() print(f"BIC Score: {lgmm.bic(data_normalized):.2f}") # 散布図に対応した色分け折れ線グラフの表示 colored_plot(df['Date'],df['Close'],labels,ticker)


図において、黄色の領域は終値や出来高の変動が比較的小さく、落ち着いた市場動向で安定したゲインを得る機会となります。青緑色の領域は、逆に終値や出来高の変動が大きく、(主にニュースなどによる)価格の大きな変動から利益を得る機会(あるいはこのようなイベント相場では動かない)となります。紫色はその中間の領域で、ポジションを調整するのに適しています。
逆張り(平均回帰)戦略再考
本ブログではこれまで、順張り(トレンドフォロー)戦略は何回か取り上げてきましたが、逆張り(平均回帰)戦略については積極的には扱ってきませんでした。これはやはり"下がっている時に買ってもまだ下がり続けるのでは"という不安が頭をよぎるからです。しかし市場価格は"真ん中に引き寄せられる"あるいは"上がり続けていてもいつかは下がる"(逆も同じ)ということは実際に市場を見ていれば当然のごとくあります。さらに、価格が反転する前にその動きを予測できれば大きな値幅の利益がとれることも事実です。そこで今回は、あらてめて逆張り(平均回帰)戦略についてとりまとめてみました。
逆張り(平均回帰)戦略で用いる指標
代表的な逆張り指標としては、ボリンジャーバンド、相対力指数(RSI)、ストキャスティクスがあります。Williams %Rも逆張りで用いられる指標です。ケルトナーチャンネルは順張りとして使われることが多いようですが、逆張りに使われることもあるため、今回取り入れました。さらに、より単純な指標ですが、Internal Bar Strength(終値と高値・安値の位置関係)及びConsecutive Up/Down(終値の連続上昇あるいは下降回数)も評価対象に加えました。
ここでは各指標についてシグナル点灯のタイミングをチャートで見ることにします。基本的なコードは、本ブログの昨年9月の投稿記事と同じです。今回は逆張り指標計算に必要な関数と戦略判定関数のみを掲載します。
まずは、Internal Bar Strenght及びConsecutive Up/Downの計算関数です。
def IBS_ConsecUpDown(df): # Internal Bar Strength (IBS) ----- df['IBS'] = (df['Close'] - df['Low']) / (df['High'] - df['Low']) # Consecutive Up/Down Days ----- up_streak = [0] # First day = 0 down_streak = [0] for i in range(1, len(df)): if df['Close'].iloc[i] > df['Close'].iloc[i - 1]: up_streak.append(up_streak[-1] + 1) down_streak.append(0) elif df['Close'].iloc[i] < df['Close'].iloc[i - 1]: down_streak.append(down_streak[-1] + 1) up_streak.append(0) else: up_streak.append(0) down_streak.append(0) df['Up_Days'] = up_streak df['Down_Days'] = down_streak return df
続いて、各指標を用いた戦略のコードとシグナル位置を示したチャートです。まずはボリンジャーバンドのシグナル判定です。
# ボリンジャーバンドの逆張り戦略によるシグナル判定 def bollinger(df,bollingerLength=20): # create dataframe df1 = df.copy() # calculate Bollinger Bands df1["upperband"], df1["middleband"], df1["lowerband"] = talib.BBANDS(df1["Close"], \ timeperiod=bollingerLength, nbdevup=2, nbdevdn=2, matype=0) # BUY signal conditions df1['BOL_buySignal'] = crossunder(df1['Close'], df1['lowerband']) # SELL signal conditions df1['BOL_sellSignal'] = crossover(df1['Close'], df1['upperband']) # return dataframe return df1.loc[:, ['timestamp','ticker','BOL_buySignal','BOL_sellSignal']]

RSI及びストキャスティクスのシグナル判定です。
# RSIとストキャスティクスによるシグナル判定 def rsi_stoch(df,rsiLength=14,r_lower=35,r_upper=65,fastk_n=14): # create dataframe df1 = df.copy() # calculate RSI df1["RSI"] = talib.RSI(df1["Close"], timeperiod=rsiLength) # calculate stochastics df1["slowk"], df1["slowd"] = talib.STOCH(df1["High"], df1["Low"], df1["Close"], \ fastk_period=fastk_n, slowk_period=3, slowk_matype=0, slowd_period=3, slowd_matype=0) # BUY signal condition df1['RSI_buySignal'] = underthreshold(df1['RSI'], r_lower) df1['STOCH_buySignal'] = (df1["slowd"] < 20) & crossover(df1["slowk"],df1["slowd"]) # SELL signal condition df1['RSI_sellSignal'] = overthreshold(df1['RSI'], r_upper) df1['STOCH_sellSignal'] = (df1["slowd"] > 80) & crossunder(df1["slowk"],df1["slowd"]) # return dataframe return df1.loc[:, ['timestamp','ticker','RSI_buySignal','RSI_sellSignal','STOCH_buySignal','STOCH_sellSignal']]


ケルトナーチャンネル及びWilliams %Rのシグナル判定です。
# ケルトナー及びWilliams Rの逆張り戦略によるシグナル判定 def kelt_willr(df): # create dataframe df1 = df.copy() # ケルトナーチャンネルを計算 (pandas_ta利用) # デフォルトでは、期間=20、ATRの乗数=2 kc = ta.kc(df1['High'], df1['Low'], df1['Close']) # 計算結果を元のDataFrameに結合 df1 = pd.concat([df1, kc], axis=1) # calculate William R df1["WillR"] = talib.WILLR(df1["High"], df1["Low"], df1["Close"], timeperiod=14) # BUY signal conditions df1['Kelt_buySignal'] = crossunder(df1['Close'], df1['KCLe_20_2']) df1['WillR_buySignal'] = underthreshold(df1['WillR'], -80) # SELL signal conditions df1['Kelt_sellSignal'] = crossover(df1['Close'], df1['KCUe_20_2']) df1['WillR_sellSignal'] = overthreshold(df1['WillR'], -20) # return dataframe return df1.loc[:, ['timestamp','ticker','Kelt_buySignal','Kelt_sellSignal',\ 'WillR_buySignal','WillR_sellSignal']]


最後にInternal Bar Strenght及びConsecutive Up Downのシグナル判定です。
# Internal Bar Strenght及びConsecutive Up Downによるシグナル判定 def ibs_updown(df,ibs_lower=0.05,ibs_upper=0.95,updown_thresh=3.5): # create dataframe df1 = df.copy() # calculate indices df1 = IBS_ConsecUpDown(df1) # BUY signal condition df1['IBS_buySignal'] = underthreshold(df1['IBS'], ibs_lower) df1['UpDown_buySignal'] = overthreshold(df1['Down_Days'], updown_thresh) # SELL signal condition df1['IBS_sellSignal'] = overthreshold(df1['IBS'], ibs_upper) df1['UpDown_sellSignal'] = overthreshold(df1['Up_Days'], updown_thresh) # return dataframe return df1.loc[:, ['timestamp','ticker','IBS_buySignal','IBS_sellSignal',\ 'UpDown_buySignal','UpDown_sellSignal']]


チャートを見てもわかる通り、トレンドに乗っている時は逆張り戦略は避けるべきです。現在トレンド相場なのかレンジ相場なのかの見極めが重要です。バックテストによる評価も順張りの指標と同様にできます。
基本編:チャートパターン分析の注意点と自動識別コード
ダブルトップ、ヘッドアンドショルダーズ(三尊)、トライアングル(三角保ち合い)などのチャートパターンは、テクニカル分析の書籍には一通り書かれていますが、実際に投資意思決定をする際に正しく活用しているかについては、確信が持てない人が多いと思われます。そこで今回は、チャートパターン分析の注意点をまとめ、さらにチャートパターンの自動識別のコードについて調べました。
チャートパターン分析の注意点
チャートパターンを分析する際の市場パターンの識別に際して投資家が陥りやすい認知バイアスや思考の落とし穴としては以下のものがあります:
(1) 存在しないパターンを見てしまう
これは「アポフェニア(apophenia)」や「パターン認識の過剰」と呼ばれる現象です。人間は本能的に秩序を探す傾向があり、ランダムな価格の動きの中にも意味のある形(チャートパターンやトレンド)を見つけようとしてしまいます。(例:ランダムなチャートの動きを「ヘッドアンドショルダー」や「三角保ち合い」と誤認する。)これにより、本質的には無意味なノイズを根拠に意思決定してしまう。
(2) 根拠のない「市場の言い伝え」を信じてしまう
過去の経験則や言い伝え(market lore)を、検証なしに鵜呑みにしてしまう傾向です。これにはテクニカル分析の決まり文句やファンダメンタルの神話が含まれます。(例:「1月に上がった株はその年ずっと上がる」「MACDのゴールデンクロスは必ず買いシグナル」)。過去に当てはまったことが、将来も同様に機能するとは限らないので注意が必要です。
(3) 過去ばかり見て未来を見ない
これは「過去バイアス(hindsight bias)」や「後知恵バイアス」とも関係があります。過去のデータや出来事にばかり目を向け、将来の変化やリスクを十分に考慮しない姿勢です。(例:過去のチャートパターンが機能したからといって、今後も通用すると思い込む)。未来の状況(市場環境、金利、政策など)は変わっており、同じ戦略が必ずしも通用しない。
(4) 状況が変化した後も元の価格目標に固執してしまう
市場環境やニュース、ボラティリティなどが変化しても、最初に立てたターゲット価格を修正しないという認知の硬直性(アンカリングバイアス)です。(例:カップウィズハンドルのターゲットが100ドルだったが、利上げ発表などの材料で流れが変わったにもかかわらず、目標を変更しない)。これにより、柔軟に戦略を見直すことができず、大きな損失や機会損失につながる。
また、チャートパターン分析の一般的な注意点として以下の項目があります:
(a)パターンの完成を待つ:未完成の形に飛びつかない。例えば、ヘッドアンドショルダーでは「ネックラインのブレイク」をもって初めて完成と見なす。
(b)だまし(フェイクアウト)への警戒:ブレイクアウトが一時的で、その後すぐに逆方向へ戻る場合がある。特にニュースや指標発表の直後はだましが多発しやすい。
(c)ボリューム(出来高)の確認:多くのパターンは出来高の変化と連動して信頼性が高まる。例:トライアングルでは収束とともに出来高が減少し、ブレイク時に急増する。
(d)他のテクニカル指標との併用:これは基本中の基本です。
チャートパターンの自動識別コード
次に、主要なチャートパターンについて自動で識別するコードを紹介します。
まずは初期設定です。
# ライブラリのインポート import pandas as pd import numpy as np from datetime import date, datetime, timedelta import matplotlib.pyplot as plt import yfinance as yf from scipy.signal import argrelextrema import warnings warnings.simplefilter(action="ignore", category=FutureWarning) # 共通設定 ticker = "4519.T" # str_prodはデータを取得する期間(例: 1d、5d、1mo、3mo、1y、2y、5y、10y、ytd、max) str_prod = "12mo" # str_itvlはデータの間隔(例: 1m、2m、5m、15m、30m、60m、90m、1h、1d、5d、1wk、1mo、3mo) str_itvl = "1d" # nwは局所最大・最小探索における近傍の幅 nw = 5 # データ獲得とローカル高値・安値計算関数 def local_min_max(ticker, str_prod, str_itvl, nwindow=5): # データ取得 df = yf.download(ticker, period=str_prod, interval=str_itvl, multi_level_index=False) df = df.dropna().reset_index() # ローカル高値・安値の検出 n = nwindow # 窓幅 highs = df['High'].values lows = df['Low'].values local_min = argrelextrema(lows, np.less, order=n)[0] local_max = argrelextrema(highs, np.greater, order=n)[0] return df, local_min, local_max
最初に"ダブルトップ"の検出です。ダブルトップは、株価が二回連続して同じような高値をつけ、その後下落するチャートパターンです。 このパターンは、株価が上昇した後に一度下落し、再び上昇して最初の高値と同じ水準で反発することで形成されます。 ダブルトップが完成するためには、二回目の下落時に最初の下落時の安値を下回る必要があります。
# ダブルトップ検出 def detect_double_top(df, peaks, tolerance=0.02): patterns = [] for i in range(len(peaks) - 1): h1 = df.iloc[peaks[i]]['High'] h2 = df.iloc[peaks[i+1]]['High'] if abs(h1 - h2) / h1 < tolerance: patterns.append((peaks[i], peaks[i+1])) return patterns df,local_min,local_max = local_min_max(ticker, str_prod, str_itvl, nwindow=nw) double_tops = detect_double_top(df, local_max) # 可視化 plt.figure(figsize=(12, 6)) plt.plot(df['Date'], df['Close'], label='Close') for p1, p2 in double_tops: plt.plot([df['Date'][p1], df['Date'][p2]], [df['High'][p1], df['High'][p2]], 'ro-') plt.title(ticker+' Double Top Detection') plt.legend() plt.show()

次は"ヘッドアンドショルダーズ"の検出です。ヘッドアンドショルダーとは、三つの高値と二つの安値で構成され、中央の高値を「頭部(ヘッド)」、左右の高値を「肩(ショルダー)」に見立てたチャートパターンのことです。 日本では「三尊天井」とも呼ばれ、主に高値圏で出現します。 ネックラインを下抜けると下落トレンドへの転換を示唆します。
# ヘッドアンドショルダー検出 def detect_head_and_shoulders(df, peaks, tolerance=0.05): patterns = [] for i in range(len(peaks) - 2): l, m, r = peaks[i], peaks[i+1], peaks[i+2] hl, hm, hr = df['High'][l], df['High'][m], df['High'][r] if hm > hl and hm > hr and abs(hl - hr) / hm < tolerance: patterns.append((l, m, r)) return patterns df,local_min,local_max = local_min_max(ticker, str_prod, str_itvl, nwindow=nw) head_shoulders = detect_head_and_shoulders(df, local_max) # 可視化 plt.figure(figsize=(12, 6)) plt.plot(df['Date'], df['Close'], label='Close') for l, m, r in head_shoulders: plt.plot([df['Date'][l], df['Date'][m], df['Date'][r]], [df['High'][l], df['High'][m], df['High'][r]], 'go-') plt.title(ticker+' Head and Shoulders Detection') plt.legend() plt.show()

最後に"トライアングルパターン"の検出です。三角保合い(トライアングルフォーメーション)は株価が上下しながらも横ばいの動きを続け(「保合い」)、その上下の動きがだんだん小さくなっていき、チャートの形が三角形のようになる状態のことを言います。その後、上下に大きく動くと言われています。
# トライアングルパターン検出 def detect_triangle(df, peaks, troughs, min_len=10, tolerance=0.05): triangles = [] for i in range(len(peaks) - 1): p1, p2 = peaks[i], peaks[i+1] t_candidates = [t for t in troughs if p1 < t < p2] if len(t_candidates) >= 1: hl1, hl2 = df['High'][p1], df['High'][p2] ll1, ll2 = df['Low'][t_candidates[0]], df['Low'][t_candidates[-1]] if abs(hl1 - hl2) / hl1 < tolerance and abs(ll1 - ll2) / ll1 < tolerance: if p2 - p1 >= min_len: triangles.append((p1, t_candidates[0], p2)) return triangles df,local_min,local_max = local_min_max(ticker, str_prod, str_itvl, nwindow=nw) troughs = argrelextrema(df['Low'].values, np.less, order=5)[0] triangles = detect_triangle(df, local_max, troughs) # 可視化 plt.figure(figsize=(12, 6)) plt.plot(df['Date'], df['Close'], label='Close') for p1, t, p2 in triangles: plt.plot([df['Date'][p1], df['Date'][p2]], [df['High'][p1], df['High'][p2]], 'm-') plt.plot([df['Date'][p1], df['Date'][p2]], [df['Low'][t], df['Low'][t]], 'm--') plt.title(ticker+' Triangle Pattern Detection') plt.legend() plt.show()

Backtraderライブラリによるバックテスト
Backtraderについては、多くの記事で用いられているものの、こみいっている感じがしたため避けていましたが、今回取り上げることとしました。
BacktraderはPythonでバックテスト・パラメータ最適化・作図などが行えるツールです。戦略の指定は、ライブラリに備わっているクラスを継承する形で行います。このようにオブジェクト指向のツールなので、私のような古株にはとっつきにくい部分があります。また、Jupyter Notebookのような対話型IDEでの利用にはそぐわないという説明も書かれています。そこで今回はVSCodeでPython仮想環境を作ってそこで動かすという方法をとりました。
まずは、ライブラリのインポート、yfinanceによる株価データの読み込みとBacktraderへの受け渡しです。
import backtrader as bt import pandas as pd import numpy as np from datetime import date, datetime, timedelta import matplotlib.pyplot as plt import yfinance as yf from IPython.display import Image import warnings warnings.simplefilter(action="ignore", category=FutureWarning) # 評価する銘柄 ticker = '6146.T' # 期間の指定 end_date = datetime.today() start_date = end_date - timedelta(days=365) # 株価データ取得 data = yf.download(ticker, start=start_date, end=end_date, interval='1d', multi_level_index=False) data.index = pd.to_datetime(data.index) data.columns = ['Open', 'High', 'Low', 'Close', 'Volume'] datafeed = bt.feeds.PandasData(dataname=data)
次に、クラスの継承による戦略の定義です。ここでは移動平均のクロス、MACDのクロスの2つの戦略を定義しています。
class SmaCross(bt.Strategy): params = (('short_period', 10), ('long_period', 30),) def __init__(self): self.sma_short = bt.indicators.SimpleMovingAverage(self.datas[0], period=self.params.short_period) self.sma_long = bt.indicators.SimpleMovingAverage(self.datas[0], period=self.params.long_period) self.crossover = bt.indicators.CrossOver(self.sma_short, self.sma_long) def next(self): if not self.position: if self.crossover > 0: self.buy() print(f'Buy at {self.datas[0].datetime.date(0)}') else: if self.crossover < 0: self.sell() print(f'Sell at {self.datas[0].datetime.date(0)}') class MACDCrossStrategy(bt.Strategy): def __init__(self): self.macd = bt.ind.MACD(self.data) self.cross = bt.ind.CrossOver(self.macd.macd, self.macd.signal) # クロス判定 def next(self): if not self.position: # ポジションを持っていないとき if self.cross > 0: # ゴールデンクロス self.buy() else: # ポジションを持っているとき if self.cross < 0: # デッドクロス self.sell()
以下はメインプログラムに相当する部分です。戦略はMACDの方を用いています。
# Cerebro実行 cerebro = bt.Cerebro() cerebro.adddata(datafeed) cerebro.addstrategy(MACDCrossStrategy) #cerebro.addstrategy(SmaCross) cerebro.broker.setcash(1_000_000) cerebro.broker.setcommission(commission=0.001) print(f'Starting Portfolio Value: {cerebro.broker.getvalue():,.2f}') cerebro.run() print(f'Final Portfolio Value: {cerebro.broker.getvalue():,.2f}') # グラフ出力 chart_file = 'result.png' cerebro.plot(style='candlestick')[0][0].savefig(chart_file, dpi=300, bbox_inches='tight') Image(open(chart_file, 'rb').read())
(以下はターミナル出力)
Starting Portfolio Value: 1,000,000.00
Final Portfolio Value: 1,004,351.25
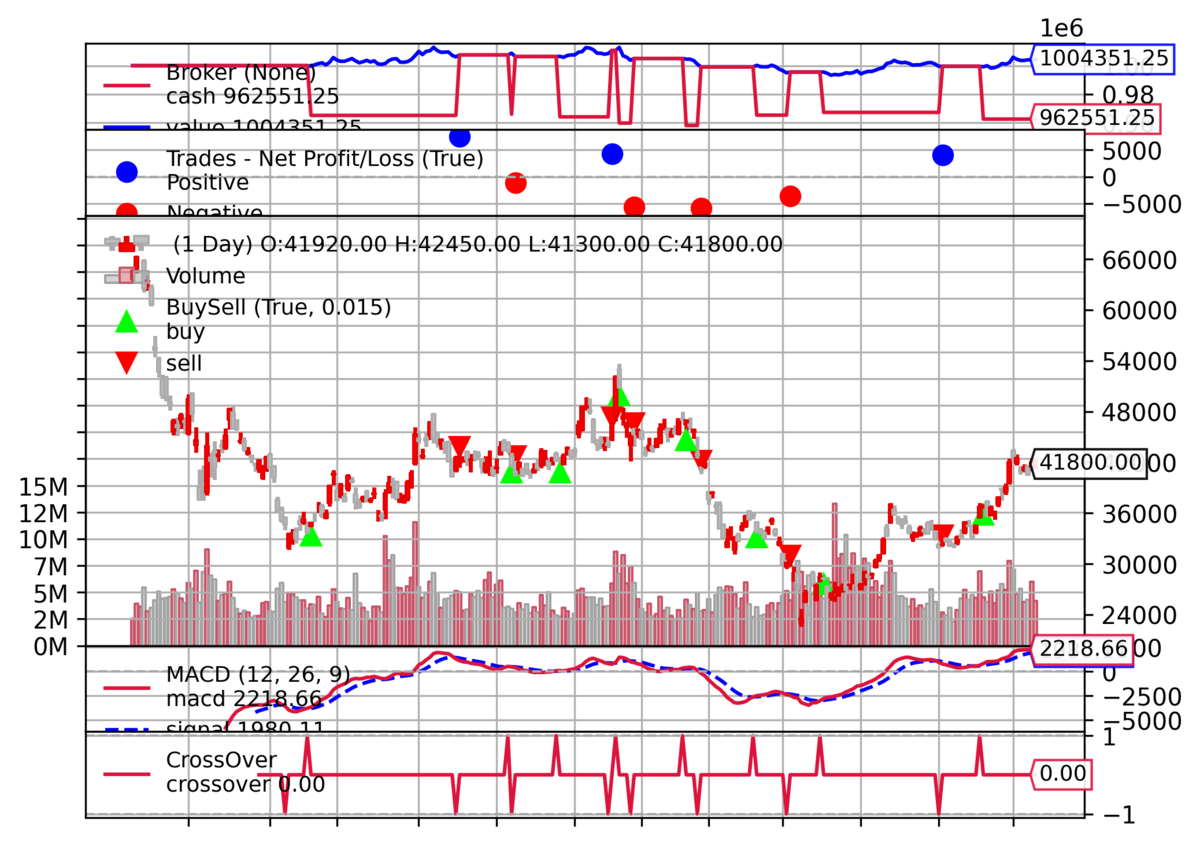
Backtraderには他にもさまざまな機能が利用可能なようです。今後取り上げていきたいと思います。
市場構造の変化指標
最近、投資関連のネット記事で、"Market Structure"をいうキーワードが目につくようになりました。その一例は、Nayab Bhuttaという人のMedium英文記事です。この著者はセンセーショナルな見出しで読者の不安と興味をかき立てるのが特徴です。今回も、「最初は多くのトレーダーと同様にテクニカル指標を信奉していたが、市場構造の変化を見ていないのは盲目に近かった」というようなことを述べています。言説はともかくも内容的には興味深いので、今回とりあげました。
BOS (Break of Structure)とCHOCH (Change of Character)は、どちらも金融市場、特に外国為替市場(FX)や株式市場で、相場のトレンド転換を予測するために使われるテクニカル分析の用語です。BOSは、相場が以前のサポートやレジスタンスを突破し、トレンドの変化を示唆するポイントを指します。一方、CHOCHは、より短い時間軸で市場構造の崩壊が見られ、トレンドの反転の初期段階を示すサインとされます。これらは特に新しい概念ということではなく、FXでは従来から一般的に用いられているようです。
以下の市場構造の変化指標を計算するコードはChatGPTなどをもとに実装したものです。
まず、ライブラリをインポートします。
import pandas as pd import numpy as np from datetime import date, datetime, timedelta import matplotlib.pyplot as plt import yfinance as yf import warnings warnings.simplefilter(action="ignore", category=FutureWarning)
次に、スイング高値・安値を検出する関数です。
def detect_swings(df, lookback=3): df['swing_high'] = df['High'][ (df['High'].shift(lookback) < df['High']) & (df['High'].shift(-lookback) < df['High']) ] df['swing_low'] = df['Low'][ (df['Low'].shift(lookback) > df['Low']) & (df['Low'].shift(-lookback) > df['Low']) ] return df
そして、BOS(構造のブレイク)と CHoCH(キャラクターの変化)を検出する関数です。
def find_bos_choch(df): structure = [] trend = 'initial' last_high = -float('inf') last_low = float('inf') for i in range(len(df)): row = df.iloc[i] if not np.isnan(row['swing_high']): if (trend == 'down' or trend == 'initial') and row['High'] > last_high: structure.append('CHoCH') # 下降トレンド → 高値を超える → 転換 trend = 'up' elif (trend == 'up' or trend == 'initial') and row['High'] > last_high: structure.append('BOS') # 上昇トレンド継続 else: structure.append(None) last_high = row['High'] elif not np.isnan(row['swing_low']): if (trend == 'up' or trend == 'initial') and row['Low'] < last_low: structure.append('CHoCH') # 上昇トレンド → 安値を割る → 転換 trend = 'down' elif (trend == 'down' or trend == 'initial') and row['Low'] < last_low: structure.append('BOS') # 下降トレンド継続 else: structure.append(None) last_low = row['Low'] else: structure.append(None) df['structure'] = structure return df
以下はメインプログラムの部分です。構造変化のあった時点のみをプリントしています。
# 評価する銘柄 ticker = '4755.T' # 期間の指定 end_date = datetime.today() start_date = end_date - timedelta(days=730) # 株価データ取得 df = yf.download(ticker, start=start_date, end=end_date, interval='1d', multi_level_index=False) # スイングポイント → BOS/CHoCH検出 df = detect_swings(df,lookback=5) df = find_bos_choch(df) # 結果の表示(BOSとCHoCHのみ) print(df[df['structure'].notna()][['High', 'Low', 'structure']])

最後に、チャートで可視化をします。
plt.figure(figsize=(14, 6)) plt.plot(df['Close'], label='Close Price') # BOS/CHoCHにマーカーを表示 for idx, row in df[df['structure'].notna()].iterrows(): color = 'green' if row['structure'] == 'BOS' else 'red' plt.scatter(idx, df.loc[idx, 'Close'], color=color, label=row['structure']) plt.title('Detecting BOS(Cont,G) and CHoCH(Rev,R)') plt.show()

この指標はテクニカル指標に取って代わるというものではなく、組み合わせて利用すべきであることはもちろんです。
クラスタリングを用いた指標パラメータの自動チューニング
今回は指標パラメータ探索関連の話題です。いつもどおりMedium英文記事からの引用ですが、興味深いアプローチなので取り上げました。用いる指標はSuper Trendというものですが、そのパラメータ決定に教師なし学習であるK-meansクラスタリングを用いています。ここではまず、Super Trendの基礎的なコードを紹介し、それから本題に入ります。
1. Super Trendの基礎コード
Super Trendは、相場の変動率を示すATRをベースにしたトレンド系のテクニカル指標です。 価格の上下に表示されるラインでトレンドを視覚的に判断できるのが特徴です。以下のコードは、Super Trendによりシグナルを生成して簡単なバックテストを行うものです。尚、ここではSuper Trendの計算にはPandas_taライブラリを用いています。
# ライブラリをインポート import yfinance as yf import pandas as pd import pandas_ta as ta from datetime import date, datetime, timedelta import matplotlib.pyplot as plt import warnings warnings.simplefilter(action="ignore", category=FutureWarning) # データ取得 ticker = '9984.T' end_date = datetime.today() start_date = end_date - timedelta(days=365) df = yf.download(ticker, start=start_date, end=end_date) df.columns = [col[0] if isinstance(col, tuple) else col for col in df.columns] df.dropna(inplace=True) # Super Trendの計算(期間=10, 乗数=3) supertrend = df.ta.supertrend(length=10, multiplier=3) df = pd.concat([df, supertrend], axis=1) # 列名(バージョンにより異なる場合あり) trend_col = [col for col in df.columns if "SUPERTd" in col][0] # trend direction line1_col = [col for col in df.columns if "SUPERTl" in col][0] # trend line line2_col = [col for col in df.columns if "SUPERTs" in col][0] # trend line # 売買シグナルの生成 df['Signal'] = 0 df.loc[(df[trend_col] == 1) & (df[trend_col].shift(1) == -1), 'Signal'] = 1 # Buy df.loc[(df[trend_col] == -1) & (df[trend_col].shift(1) == 1), 'Signal'] = -1 # Sell # ポジション保持(ロングのみ) df['Position'] = df['Signal'].replace(to_replace=0, method='ffill') df['Position'].fillna(0, inplace=True) # リターンとストラテジー df['Return'] = df['Close'].pct_change() df['Strategy_Return'] = df['Position'].shift(1) * df['Return'] df[['Cumulative_Market', 'Cumulative_Strategy']] = (1 + df[['Return', 'Strategy_Return']]).cumprod() # チャート描画(価格 + Super Trend + シグナル) plt.figure(figsize=(14, 6)) plt.plot(df['Close'], label='Close Price', alpha=0.5) plt.plot(df[line1_col], label='Super Trend Line 1') plt.plot(df[line2_col], label='Super Trend Line 2') plt.scatter(df.index[df['Signal'] == 1], df['Close'][df['Signal'] == 1], label='Buy Signal', marker='^', color='green') plt.scatter(df.index[df['Signal'] == -1], df['Close'][df['Signal'] == -1], label='Sell Signal', marker='v', color='red') plt.title(ticker + ' Stock price with Super Trend Signals') plt.legend() plt.grid() plt.show()

2. クラスタリングを用いたSuper Trendパラメータの自動チューニング
次は今回の本題である、クラスタリングを用いたパラメータ値決定のコードです。本コードは、ATRやSuper Trendの計算、さらにクラスタリングについても外部ライブラリを用いず自前で計算を行っています。
まず、ライブラリのインポートと初期設定を行います。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib.dates as mdates import matplotlib.style as mplstyle import yfinance as yf # User parameters TICKER = "9984.T" # Ticker symbol to pull from Yahoo Finance # Time range for the analysis START_DATE = "2022-01-01" END_DATE = "2025-06-13" # ATR_LENGTH controls how reactive the ATR (Average True Range) is. # Shorter = more sensitive to price spikes. Longer = smoother. ATR_LENGTH = 10 # These define the range of SuperTrend factors to test. # We'll run the SuperTrend indicator across multiple values between MIN_MULT and MAX_MULT. MIN_MULT = 1.0 # smallest factor (tightest stop) MAX_MULT = 5.0 # largest factor (widest stop) STEP = 0.5 # spacing between factors (e.g., 1.0, 1.5, 2.0, ...) # PERF_ALPHA controls smoothing of the performance metric. # Lower = more reactive to recent price behavior. PERF_ALPHA = 10 # We'll cluster the performance results into 3 groups (Best, Average, Worst) # and select the factor from the chosen group. FROM_CLUSTER = "Best" # Options: "Best", "Average", or "Worst" # Maximum number of iterations for the k-means clustering step MAX_ITER = 1000 # Note: maxData isn’t needed here, but could be used to limit data length if desired.
次に、データをダウンロードし、中値(列名"h12")を計算します。
# 1) Download data df = yf.download(TICKER, start=START_DATE, end=END_DATE, interval="1d", multi_level_index=False) if df.empty: raise ValueError("No data returned from yfinance") df.dropna(subset=["High","Low","Close"], inplace=True) # hl2 df["hl2"] = (df["High"] + df["Low"]) / 2.0
次にATRを計算します。
# 2) Compute ATR df["prev_close"] = df["Close"].shift(1) df["tr1"] = df["High"] - df["Low"] df["tr2"] = (df["High"] - df["prev_close"]).abs() df["tr3"] = (df["Low"] - df["prev_close"]).abs() df["tr"] = df[["tr1","tr2","tr3"]].max(axis=1) # Use EMA for ATR df["atr"] = df["tr"].ewm(alpha=2/(ATR_LENGTH+1), adjust=False).mean() df.dropna(inplace=True) df.reset_index(drop=False, inplace=True) # We'll keep a normal numeric index plus a 'Date' column n = len(df) # Helper: sign --> Returns +1 for up, -1 for down, 0 for no change. used to track price direction def sign(x): # x > 0 => 1, x < 0 => -1, x=0 => 0 return np.where(x>0, 1, np.where(x<0, -1, 0))
そして、評価するパラメータ値の各々についてSuper Trendを計算して、結果を蓄積します。
# 3) Compute supertrend for each factor def compute_supertrend(df, factor, perf_alpha): """ For each bar: up = hl2 + atr * factor dn = hl2 - atr * factor We track 'trend' (1 = bullish, 0 = bearish), 'upper', 'lower', 'output', 'perf'. 'perf' is updated with an EMA of sign-based price changes. """ arr_close = df["Close"].values arr_hl2 = df["hl2"].values arr_atr = df["atr"].values n = len(df) # オリジナルのコードではグローバル変数 trend = np.zeros(n, dtype=int) upper = np.zeros(n, dtype=float) lower = np.zeros(n, dtype=float) output = np.zeros(n, dtype=float) perf = np.zeros(n, dtype=float) # Init trend[0] = 1 if arr_close[0] > arr_hl2[0] else 0 upper[0] = arr_hl2[0] lower[0] = arr_hl2[0] output[0] = arr_hl2[0] perf[0] = 0.0 for i in range(1, n): up = arr_hl2[i] + arr_atr[i]*factor dn = arr_hl2[i] - arr_atr[i]*factor # Determine new trend if arr_close[i] > upper[i-1]: trend[i] = 1 elif arr_close[i] < lower[i-1]: trend[i] = 0 else: trend[i] = trend[i-1] # Update upper & lower if arr_close[i-1] < upper[i-1]: upper[i] = min(up, upper[i-1]) else: upper[i] = up if arr_close[i-1] > lower[i-1]: lower[i] = max(dn, lower[i-1]) else: lower[i] = dn # Performance metric diff_sign = sign(arr_close[i-1] - output[i-1]) # Weighted EMA approach perf[i] = perf[i-1] + 2/(perf_alpha+1)*((arr_close[i] - arr_close[i-1]) * diff_sign - perf[i-1]) # Output output[i] = lower[i] if trend[i] == 1 else upper[i] return { "trend": trend, "upper": upper, "lower": lower, "output": output, "perf": perf, "factor": factor } factors = np.arange(MIN_MULT, MAX_MULT + 0.0001, STEP) st_results = [] for f in factors: st = compute_supertrend(df, f, PERF_ALPHA) st_results.append(st) # We'll cluster using the final performance value perf_vals = np.array([res["perf"][-1] for res in st_results]) fact_vals = np.array([res["factor"] for res in st_results])
次は、K-meansクラスタリングを行っています。そして、指定したクラスターに属するパラメータ値の平均を最終的なパラメータ値としています。
# 4) K-means clustering (k=3) def k_means(data, factors, k=3, max_iter=1000): # Initialize centroids from quartiles c1, c2, c3 = np.percentile(data, [25, 50, 75]) centroids = np.array([c1, c2, c3]) for _ in range(max_iter): clusters = {0: [], 1: [], 2: []} cluster_factors = {0: [], 1: [], 2: []} # Assign each data point for d, f in zip(data, factors): dist = np.abs(d - centroids) idx = dist.argmin() clusters[idx].append(d) cluster_factors[idx].append(f) # Recompute centroids new_centroids = np.array([np.mean(clusters[i]) if len(clusters[i])>0 else centroids[i] for i in range(k)]) # Check if converged if np.allclose(new_centroids, centroids): break centroids = new_centroids return clusters, cluster_factors, centroids clusters, cluster_factors, centroids = k_means(perf_vals, fact_vals, k=3, max_iter=MAX_ITER) # Sort clusters by centroid order = np.argsort(centroids) sorted_clusters = {i: clusters[j] for i,j in enumerate(order)} sorted_cluster_factors = {i: cluster_factors[j] for i,j in enumerate(order)} sorted_centroids = centroids[order] # 'Best' => index 2, 'Average' => index 1, 'Worst' => index 0 if FROM_CLUSTER == "Best": chosen_index = 2 elif FROM_CLUSTER == "Average": chosen_index = 1 else: chosen_index = 0 if len(sorted_cluster_factors[chosen_index])>0: target_factor = np.mean(sorted_cluster_factors[chosen_index]) else: target_factor = factors[-1] # Compute the average performance for that cluster if len(sorted_clusters[chosen_index])>0: target_perf = np.mean(sorted_clusters[chosen_index]) else: target_perf = 0.0
そして、最終的なパラメータ値をもとにSuper Trendをベースとした戦略で収益を評価します。
# 5) Recompute final supertrend with target_factor st_final = compute_supertrend(df, target_factor, PERF_ALPHA) ts = st_final["output"] os = np.zeros(n, dtype=int) # 1 = bullish, 0 = bearish # The logic: os = close>upper => 1, close<lower => 0, else same as prior os[0] = 1 if df["Close"].iloc[0] > st_final["upper"][0] else 0 for i in range(1, n): c = df["Close"].iloc[i] up = st_final["upper"][i] dn = st_final["lower"][i] if c > up: os[i] = 1 elif c < dn: os[i] = 0 else: os[i] = os[i-1] # Build an adaptive MA for the trailing stop den_close_diff = (df["Close"] - df["Close"].shift(1)).abs() den = den_close_diff.ewm(alpha=2/(PERF_ALPHA+1), adjust=False).mean() den_val = den.iloc[-1] if den.iloc[-1] != 0 else 1e-9 perf_idx = max(target_perf, 0) / den_val perf_ama = np.zeros(n, dtype=float) perf_ama[0] = ts[0] for i in range(1, n): perf_ama[i] = perf_ama[i-1] + perf_idx*(ts[i] - perf_ama[i-1])
最後に、結果を出力します。尚、ここでのトレンドラインの色は米国式のため、上の図とは逆になっています。またSuper Trendのパラメータ値が異なるため、シグナルのタイミングも異なっています。
# 6) Plotting # mplstyle.use("dark_background") fig, ax = plt.subplots(figsize=(18,9)) dates = mdates.date2num(df["Date"]) # Plot close price ax.plot(dates, df["Close"], color="silver", lw=1.2, label="Close Price") # Build separate lines for bullish/bearish trailing stop ts_bull = np.where(os==1, ts, np.nan) ts_bear = np.where(os==0, ts, np.nan) ax.plot(dates, ts_bull, color="teal", lw=1.2, label="Bullish Stop") ax.plot(dates, ts_bear, color="red", lw=1.2, label="Bearish Stop") # Plot AMA line ax.plot(dates, perf_ama, color="orange", lw=1.0, alpha=0.7, label="Trailing Stop AMA") # Plot signals where os changes for i in range(1, n): if os[i] != os[i-1]: # If os[i] = 1 => bullish signal if os[i] == 1: ax.scatter(dates[i], ts[i], marker='^', s=80, color="teal", edgecolor="white", zorder=5) else: ax.scatter(dates[i], ts[i], marker='v', s=80, color="red", edgecolor="white", zorder=5) ax.set_title(f"SuperTrend (Clustering) - {TICKER} [Factor ~ {target_factor:.2f}]", color="white") ax.set_xlabel("Date", color="white") ax.set_ylabel("Price", color="white") ax.legend(loc="upper left") # Format date axis ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) fig.autofmt_xdate() plt.grid(True, alpha=0.2) plt.tight_layout() plt.show() # 採用された係数の印刷 print("最終的に採用されたSuperTrendの係数 = ", target_factor)

![]()
実務上は、上記の最終的なパラメータ値を用いてSuper Trendによるシグナルを計算することになります。尚、本記事の他にも、K-meansクラスタリングのような「教師なし学習」を市場予測に用いる例は最近よくみかけるようになりました。