【注記】最初に投稿したコードはGoogle Colaboratoryでは動作しますが、Dockerではエラーで動作しないものでした。ダッシュボードはデプロイしなければほとんど意味がなく、現状ではDocker環境がデプロイには最もよい方法と考えらるため、Dockerでエラーなく動いたコードに全面的に置き換えました。
(2023-09-15) docker-compose.ymlに不要な記述があったため修正しました。
一か月以上前にPythonのdashライブラリを用いたインタラクティブなデータテーブルの表示のコードについて投稿しました。それからさらに発展し、今度はいくつかのデータテーブルとグラフを組み合わせたダッシュボードの作成に挑戦します。
前回と同じくDashライブラリを用います。ダッシュボードの作成にはdash_bootstrap_components(dbc)を用います。出力されるhtml画面レイアウトの見た目をよくするためには様々なパラメータを指定する必要があります。幸いdbcを用いたダッシュボードの画面設計については数多くのチュートリアルYouTubu動画があり、ここでもそのうちの一つを参考にしました。
前回と同様に、全国都道府県の様々な指標を収録したエクセルファイルからデータを入力して、各種指標をダッシュボードに表示させます。
from dash.dependencies import Output, Input, State
import dash_bootstrap_components as dbc
import dash_core_components as dcc
import dash_html_components as html
import plotly.express as px
from flask import Flask
import pandas as pd
import dash
import numpy as np
import dash_table
import plotly.graph_objects as go
from dash_table import FormatTemplate
from dash.dash_table.Format import Format
まず最初に、appという「箱」を作ります。これをサーバー上で走らせることになります。
server = Flask(__name__)
app = dash.Dash(server=server, external_stylesheets=[dbc.themes.FLATLY])
app.title = 'Dashboard'
次に、原データのExcelファイルを読み込み、データ整形用の補助変数を作成します。
df1 = pd.read_excel('都道府県各種指標.xlsx',sheet_name='data')
df1 = df1.assign(ch_year = df1['年度'].apply(lambda x: str(x)+'年'))
df1 = df1.assign(id_pref = df1['地域コード']+df1['都道府県'])
df1.sort_values('ch_year',ascending=True,inplace=True)
my_list = df1.columns
to_remove = ['年度','地域コード','都道府県','ch_year','id_pref']
remained_list = [i for i in my_list if i not in to_remove]
次に、データテーブルの作成に関する記述を行っておきます。
columns1 = [
dict(id='都道府県',name='都道府県'),
dict(id='2007年', name='2007年度'),
dict(id='2008年', name='2008年度'),
dict(id='2009年', name='2009年度'),
dict(id='2010年', name='2010年度'),
dict(id='2011年', name='2011年度'),
dict(id='2012年', name='2012年度'),
dict(id='2013年', name='2013年度'),
dict(id='2014年', name='2014年度'),
dict(id='2015年', name='2015年度'),
dict(id='2016年', name='2016年度'),
dict(id='2017年', name='2017年度'),
dict(id='2018年', name='2018年度')
]
def create_dash_table(df):
return dash_table.DataTable(
data=df.to_dict('records'),
columns=columns1,
style_cell={'fontsize':20, 'font-family':'IPAexGothic'},
style_cell_conditional=[{'if':{'column_id':c},'textAlign':'left'} for c in ['都道府県']],
style_data={'color':'black','backgroundColor':'white'},
style_data_conditional=[{'if':{'row_index':'odd'},'backgroundColor':'rgb(220,220,220)'}],
style_header={'backgroundColor':'rgb(210,210,210)','color':'black','fontWeight':'bold'} )
さて、ここからいよいよ山場であるレイアウトの記述です。基本的に行(dbc.Row)を切った後その中に列(dbc.Col)を切っていきます。
app.layout = dbc.Container([
dbc.Row(
dbc.Col(
html.H2("日本の都道府県の各種指標"), width={'size': 12, 'offset': 0, 'order': 0}),
style = {'textAlign': 'center', 'paddingBottom': '1%'}),
dbc.Row(
dbc.Col(
dcc.Loading(
children=[
html.Div(
dcc.Dropdown(id='dropdown1-kpi',options=[{'label':i,'value':i} for i in remained_list],value='総人口'),
style={'width':'30%','display':'inline-block','margin-right':10}),
html.Div(
dcc.Dropdown(id='dropdown1-plot',options=[{'label':i,'value':i} for i in ['箱ひげ図','散布図','バイオリン']],value='箱ひげ図'),
style={'width':'30%','display':'inline-block','margin-right':10}),
dcc.Graph(id='box-plot')
],color='#000000',type='dot',fullscreen=True ))),
dbc.Row(
dbc.Col(
dcc.Loading(
children=[
html.Div(
dcc.Dropdown(id='dropdown2-pref',options=[{'label':i,'value':i} for i in df1['都道府県'].unique()],value='東京都'),
style={'width':'30%','display':'inline-block','margin-right':10}),
html.Div(
dcc.Dropdown(id='dropdown2-kpi',options=[{'label':i,'value':i} for i in remained_list],value='総人口'),
style={'width':'30%','display':'inline-block','margin-right':10}),
html.Div(
dcc.Dropdown(id='dropdown2-plot',options=[{'label':i,'value':i} for i in ['棒グラフ','折れ線グラフ']],value='棒グラフ'),
style={'width':'30%','display':'inline-block','margin-right':10}),
dcc.Graph(id='basic-plot')
],color='#000000',type='dot',fullscreen=True ))),
dbc.Row(
dbc.Col(
dcc.Loading(
children=[
html.Div(
dcc.Dropdown(id='dropdown3-kpi',options=[{'label':i,'value':i} for i in remained_list],value='総人口'),
style={'width':'30%','display':'inline-block','margin-right':10}),
html.Div(id='datatable-paging',children=[])
],color='#000000',type='dot',fullscreen=True )))
])
次に、コールバックと実行関数の記述です。
一番目に分布グラフについての記述です。
@app.callback(
Output('box-plot','figure'),
[Input('dropdown1-kpi','value'),Input('dropdown1-plot','value')])
def update_figure(inval1,inval2):
filtered_df=df1
if inval2 == '箱ひげ図':
fig=px.box(filtered_df,x='ch_year',y=inval1,hover_name='都道府県')
fig.update_layout(transition_duration=500)
return fig
elif inval2 == '散布図':
fig=px.scatter(filtered_df,x='ch_year',y=inval1,hover_name='都道府県')
fig.update_layout(transition_duration=500)
return fig
else:
fig=px.violin(filtered_df,x='ch_year',y=inval1,hover_name='都道府県')
fig.update_layout(transition_duration=500)
return fig
return
二番目に基本グラフについての記述です。
@app.callback(
Output('basic-plot','figure'),
[Input('dropdown2-pref','value'),Input('dropdown2-kpi','value'),Input('dropdown2-plot','value')])
def update_figure(inval1,inval2,inval3):
filtered_df=df1[df1['都道府県']==inval1]
if inval3 == '棒グラフ':
fig=px.bar(filtered_df,x='ch_year',y=inval2)
fig.update_layout(transition_duration=500)
return fig
else:
fig=px.line(filtered_df,x='ch_year',y=inval2)
fig.update_layout(transition_duration=500)
return fig
続いてデータテーブルについてのコールバックと実行関数の記述です。
@app.callback(
Output('datatable-paging','children'),
[Input('dropdown3-kpi','value')])
def update_table(inval1):
df502=df1.pivot(index='id_pref',columns='ch_year',values=inval1)
df502.reset_index(inplace=True)
df502=df502.assign(都道府県=df502['id_pref'].apply(lambda x: x[6:]))
return create_dash_table(df502)
最後にサーバを起動します。Docker環境で実行する場合、docker-compose.ymlなどによりポート番号の指定を行います。ブラウザから指定ポートへアクセスして動作を確認します。
if __name__=='__main__':
app.run_server()
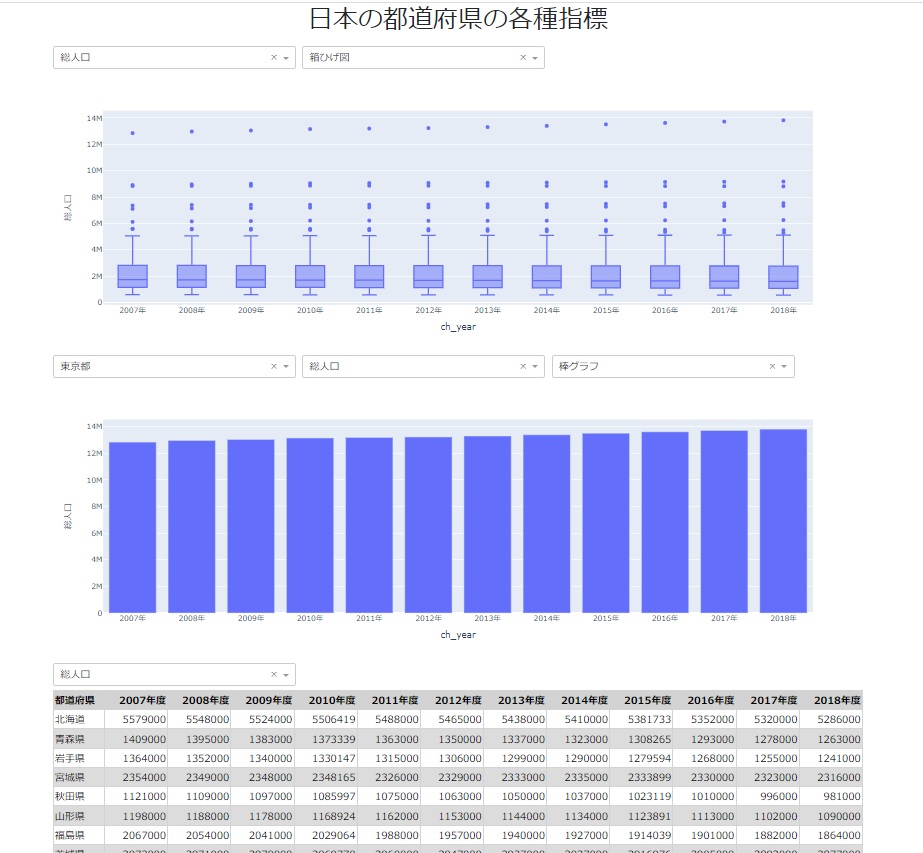
各グラフ要素のドロップダウンリストを変更すると対応する図も変更されます。本コードは、現行のDocker Desktop for Windowsで動作します。またAWS上にデプロイして動作することも確認しています。
尚、Dockerで必要になるdocker-compose.ymlは以下のようにしています。
version: '3.7'
services:
dashboard:
build:
context: ./
container_name: dash-app_dashboard
restart: always
ports:
- 8050:80








